|
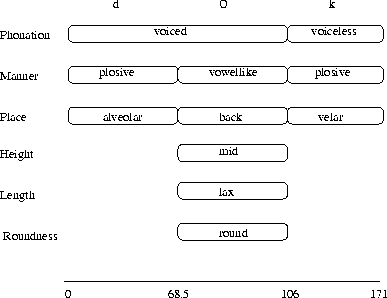
In this figure, the syllable /dOk/ is depicted in
terms of the features defined above. This representation assumes the
synchronisation function to be the same across features as can be seen in the
fact that the feature boxes are all of the same length.
OCP_phonation:
<> == Null
<[voiced]> == [voiced] <>
<[voiced] [voiced]> == <[voiced]>
<[voiceless]> == [voiceless] <>
<[voiceless] [voiceless]> == <[voiceless]>.
However, this
definition is not very general since it only applies to the phonation tier. The OCP
can be represented more elegantly and more generally by the use of a variable $F
that ranges over features.
OCP:
<> == Null
<$F> == $F <>
<$F $F> == <$F>.
This definition of
the OCP is more general since it applies to any two identical features
and can be regarded as a smoothing operation over features. Since we require
that the OCP applies to each tier in the autosegmental representation,
each resulting tier then has its own melody. In order to cater for such an
autosegmental description, we must extend the syllable node as follows:
Syllable:
...
<melody> == OCP:<<structure>>.
We can now infer the
following melodies for the phonation and manner tiers for the syllable /dOk/:
S_dOk: <melody phonation> = [voiced] [voiceless] <melody manner> = [plosive] [vowellike] [plosive].
Exercise 6045
Give the place, manner and phonation melodies for S_tee, S_E6, and the syllables that you defined earlier.