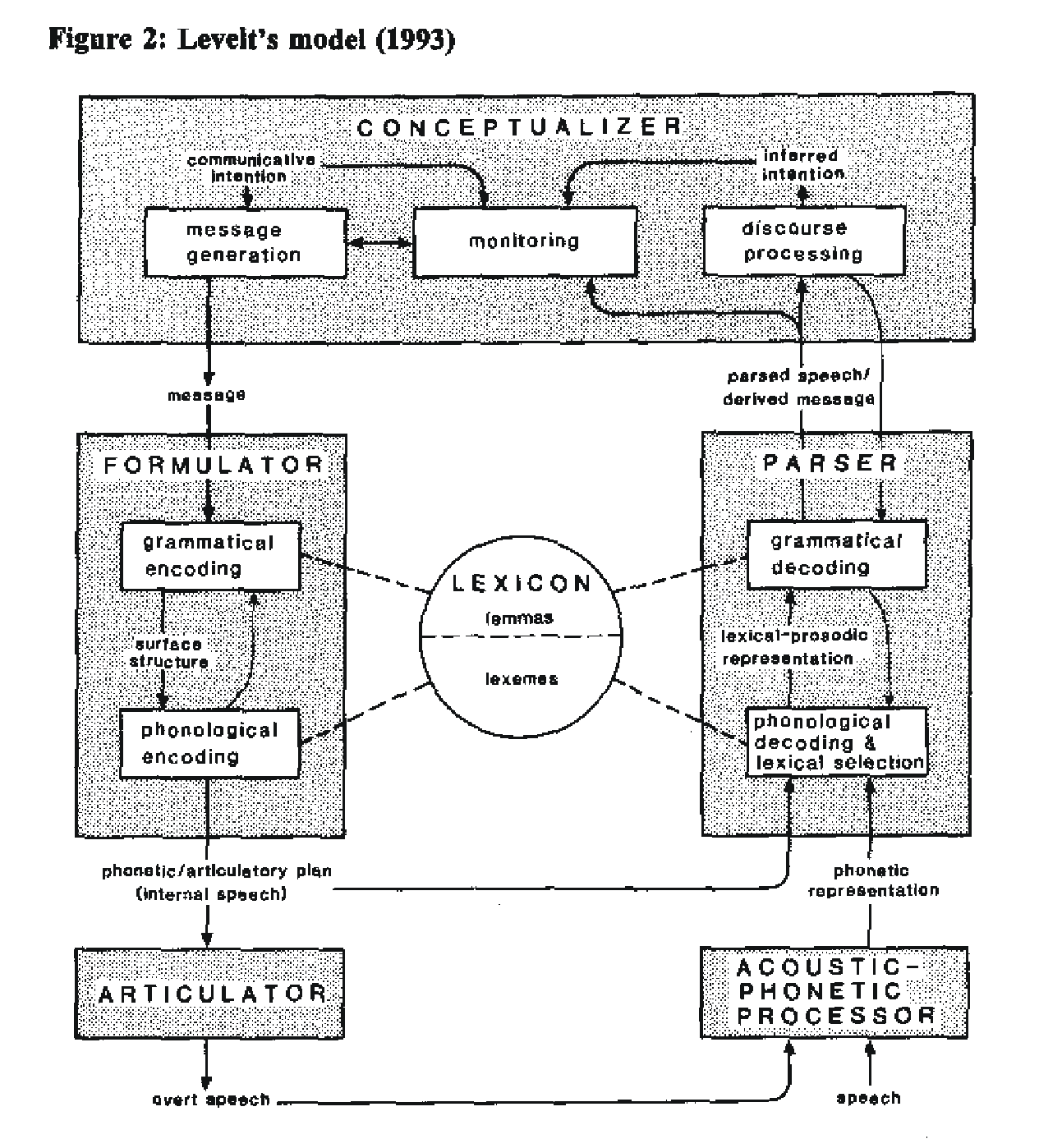
列維特模組(Levelt’s Model)
‘列維特模組’(Levelt’s model,亦稱做為序列模組“serial model”)是在西元1989年威廉•列維特(Willem J. M. Levelt) 所提出言語生成模組中,最著名的一個。此序列模組包含了連結系統(connectionist systems)但其整體設計運用了序列典範(serial paradigm)。威廉所採用的序列模組是根源於他對錯誤校正資料的分析。而這些資料又是從一次龐大的實驗中蒐集而來,並指出連結模組無法說明時間遲滯的原因為何。
列維特模組可分為三種主要部分:
1. 概念成型器(conceptualizer):意念及適切的概念結構之生成。
2. 轉化器(formulator):將概念結構轉化成文法和音韻的語碼。
3. 發音器(articulator):利用音韻語碼來促使肌肉發出語音。
資料來源:http://chat.carleton.ca/~ceby/Serial.html
列維特所要大力強調的是這樣由語言角度所呈現出來的知識必須要轉換成命題式的形式。這是指說這樣子的知識必須要有和它所指涉的事件狀態所相關的真實價值。他主張雖然在大腦心智中有許多知識呈現的形式,但是當一段言辭產生時,知識必須要命題式的譯成語碼。他所套用的是由傑肯杜夫(Jackendoff)在1983年,針對概念組織所提出的理論。
列維特繼續擴展他的模組來處理更多的挑戰與資料。他已經將序列方法和基準方法(serial and modular approach)與延伸活化系統(a spreading activation system)的部分方面做合併,尤其,是運用在他的詞彙存取模組(model of lexical access)。因為這個模組是用理解系統(comprehension system)來當作校定錯誤的編輯器,所以也被認為是稍有不足。先前的序列模組是採用分離式的編輯系統。到目前為止,列維特的模組是用來反對測試的最好模組,並且可以解釋大部分的資料,但是他的模組是以來自受制實驗的資料為基礎,這也是最被批評的地方。這點可以從被觀察到的序列性來說明。在自然的情形下,一個更混雜的模組可能比較適當些。
資料來源:http://chat.carleton.ca/~ceby/Serial.html