Processing of Written Language
Processing of Written Language
one of the most difficult topics is NLP (Natural Language Processing) : removal of the language barrier between people. This involves communicating with application programs or expert systems in the most natural and efficient format. Pattern recognition in speech and visual scene analysis are therefore significant.
Success in natural language understanding has been slow in coming and achieved at great cost and effort. The goal of natural language translation was one of the first attempted by AI researchers, and failure to reach it proved to be one of AI's greatest disappointments. However, analysis of past failures allowed progress has been made to generalise this "translation" machine.
Ways of Communication of Languages
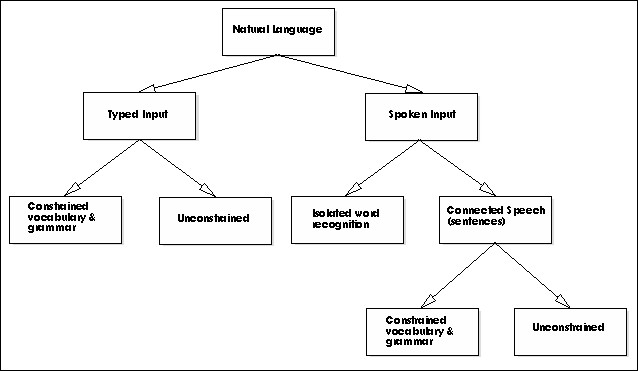
The majority of human linguistic communication occurs as speech. Written language was only a recent invention and plays a less central role. However, processing written language (assuming an unambiguous representation) is easier than processing speech in general. For example, building a program that understands speech requires all facilities of a written language understander as well as enough knowledge to handle noise and ambiguities of audio signal. Thus it is useful to split the problem into two subtasks:
Processing written text : using lexical, syntactic and semantic knowledge of language
Processing spoken language : using all information needed above, and additional knowledge about phonology

Steps in the Process
One pitfall in processing language is that it is tempting to define the language simply as a set of strings, without reference to understanding the context. However, in order to increase realism and accuracy, we must represent the language as a pair: (source language, target representation). The target representation would be chosen relevant to the situation. Hence it is possible to depict this as a mapping from the piece of language to some representation.
In overview, to achieve this we need to define precisely what the underlying task and target representation would look like. This approach can be broken down into several steps:
Morphological Analysis
² Singleton words are analysed into their respective components
² Non-word tokens (e.g. punctuation) are categorised separately
Syntactic Analysis
² Structure holds linear sequences of related words
² Word sequence is rejected if it violates the language rules for how words may be combined For example, an English analyser would reject: "Girl the walk computer do."
Semantic Analysis
² Structures created by syntactic analyser are assigned meanings
² Mapping exists between syntactic structures and objects in task domain
² Structures with no mappings may be rejected (semantically anomalous). For example, the sentence: "Colorless green ideas sleep furiously" [Chomsky, 1957] would be rejected
Discourse Integration
² Meaning of an individual sentence could influence other sentences that precede or follow it. For example, the word "it" in the sentence: "George needed it" depends on the preceding context; while the word "George" could influence the meaning of later sentences, such as "He always laughs".
Pragmatic Analysis
² Structure representing what was said is interpreted to determine what is required to be done
² Application of a set of rules that characterise co-operative dialogues
² Translation from knowledge-based representation to a command executed by the system
Complete separation of these phases is difficult. These steps all interact in some way, and can be processed sequentially or in parallel. However, if there is dependence from one phase to another, it is critical to process in an order which satisfies the overall performance.
Problems with Natural Language Processing
Reference
http://cslu.cse.ogi.edu/HLTsurvey/ch8node9.html